 rss
rss
Telldus Live! scheduler status
On Thursday 12th December we experienced issues with the scheduler for TellStick Net. This is an explanation of what happened, what we did to solve the problems and what we are going to do to prevent similar issues in the future.
What happened?
To execute all the scheduled jobs in Telldus Live! we use multiple servers. We monitor the number of connected TellStick Net closely and adds more servers when needed. The scheduler works by having some dispatcher servers that decides which job should be executed by which worker servers. The worker servers then receive these jobs and starts to execute them. Every minute we start up new dispatcher processes to dispatch new jobs to the workers.
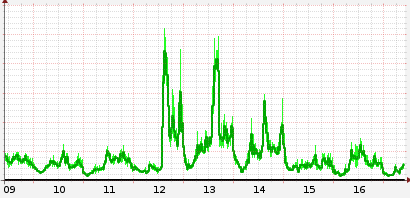
Suddenly last Thursday, without any warning, something made the database really slow. This literally took us by suprise. See on the image below.

This led to the dispatchers not beeing able to finish their tasks in time and new dispatchers began their work the next minute. These wasn't able to finish either so the next minute even more dispatchers started. All these dispatchers clogged up the already slow database resulting in that no jobs were executed at all.
The overall slow system performance unfortunately also affected the Telldus Live! webpage and third party applications making manual control slow.
What we did
The most urgent action was to manually stop the old dispatchers on every server. This made the scheduler working but unfortunately a lot of jobs where not executed, especially during peek hour. On friday we started working on finding the bugs making the dispatcher spin out of control. Unfortunately these fixes was not finished until Friday evening, again resulting in that a lot of jobs were not executed on Friday.
During Friday evening and Saturday we saw that the fixes where working and even dispite the slow database almost all of the jobs where executed. During peek hour there was 10-15 minutes delay on some jobs though. On Sunday the issues with the slow database where resolved.
What we are going to do
We have seen that we still have some bottlenecks in the scheduler. To fix this will take time but it is our top priority. We have several improvements we want to add, some will be deployed in the near future and others will be an ongoing project. Our first task is to extract the dispatchers as a separate system and give them dedicated resources. This will prevent other services to affect the scheduler. If some other part makes the system slow or not working, this should not affect the scheduler. Hopefully we will begin tests this week. The long plan is to alter the architecture of the scheduler making it especially the dispatchers easier to scale linearly. We cannot say when we could start our first tries of this yet.
If someone still experience issues with the scheduler, we would like to know. Please send a support request with the time and devices that was not executed and we can investigate manually.
The scheduler functionality in "My Events" was not affected by these problems, other than the perodical general slowness in the system.
We are very sorry for all this. Having a reliable service is of course top priority for us.
Attachments (1)
- scheduler.png (8.4 KB) - added by 11 years ago.
{kind=link}
Download all attachments as: .zip
Comments
No comments.